斯坦福 CS448B 04 探索性数据分析
TLDR
本文包含我对斯坦福 CS448B(数据可视化)课程的笔记,特别关注第四讲关于探索性数据分析的内容。我将讨论探索性数据分析的重要性、背后的原则,并探索各种数据可视化技术,包括使用指导元素、表达性、有效性、对比和模式感知的支持、数据分组和排序、数据转换、减少认知负担以及一致性。我还将介绍各种图表类型,如折线图、柱状图、堆叠面积图等,提供示例并讨论它们的设计考虑因素。
原文
笔记
统计学的兴��起(1900-1950 年代)
- 统计学和社会科学中形式化方法的兴起 —
Fisher、Pearson等 - 图形方法创新较少
- 应用和普及的时期
- 图形方法进入教科书、课程 和主流使用
数据分析的未来,John W. Tukey(1962)
当今有四个主要因素影响着数据分析:
- 统计学的形式理论
- 计算机和显示设备的加速发展
- 更多更大的数据集
- 许多学科对量化的强调
过去几十年见证了统计学形式理论的兴起,通过将变异性限定在随机抽样的假设中来"合法化"变异性,这些抽样通常被假定涉及严格指定的分布,并通过强调狭义优化的技术并声称以"已知"的错误概率做出陈述来恢复安全感。
虽然统计理论对数据分析的一些影响是有帮助的,但其他一些则不然。
对我们而言,暴露,即有效地展示数据以显示意外情况,是数据分析的主要部分。形式统计学几乎没有为暴露提供任何指导;事实上,目前还不清楚如何将适合暴露探索性特点的非正式性和灵活性融入到迄今为止提出的任何形式统计结构中。 没有什么——不是数学的严密逻辑,不是统计模型和理论,不是现代计算机强大�的算术能力——能够替代这里有见识的人类思维的灵活性。
因此,方法和技术都需要有结构,以便于人类参与和干预。
数据清洗
在分析之前,人们通常需要操作数据。任务包括重新格式化、清洗、质量评估和整合
- GPTs
- 编写自定义脚本
- 在电子表格中手动操作
- Trifacta Wrangler: http://trifacta.com/products/wrangler/
- Open Refine: http://openrefine.org
- Arquero.js: https://observablehq.com/@uwdata/introducing-arquero
如何衡量可视化的质量?
"一个好的可视化的第一个迹象是它能显示你��数据中的问题......我参与过的每一个成功的可视化都有这样一个阶段,你会意识到,'天哪,这些数据不是我想象的那样!'
所以,你已经发现了一些东西。"
- Martin Wattenberg
说实话,上述观点是我评估可视化价值的关键标准之一。如果用户看到可视化项目后感到平淡无奇,那么该项目可以被认为是平庸的或失败的。一个优秀的可视化项目必须帮助用户发现有价值的信息。例如安斯库姆四重奏
数据质量障碍
- 缺失数据
没有测量值,被编辑过,...? - 错误值
拼写错误,异常值,...? - 类型转换
例如,邮编转经纬度 - 实体解析
同一事物的不同值? - 数据整合
合并数据时的努力/错误
预测数据可能出现的问题。
围绕这些问题有许多研究!
保持怀疑态度
- 检查数据质量和你的假设
- 从单变量摘要开始,然后 考虑变量之间的关系
- 避免过早固定!
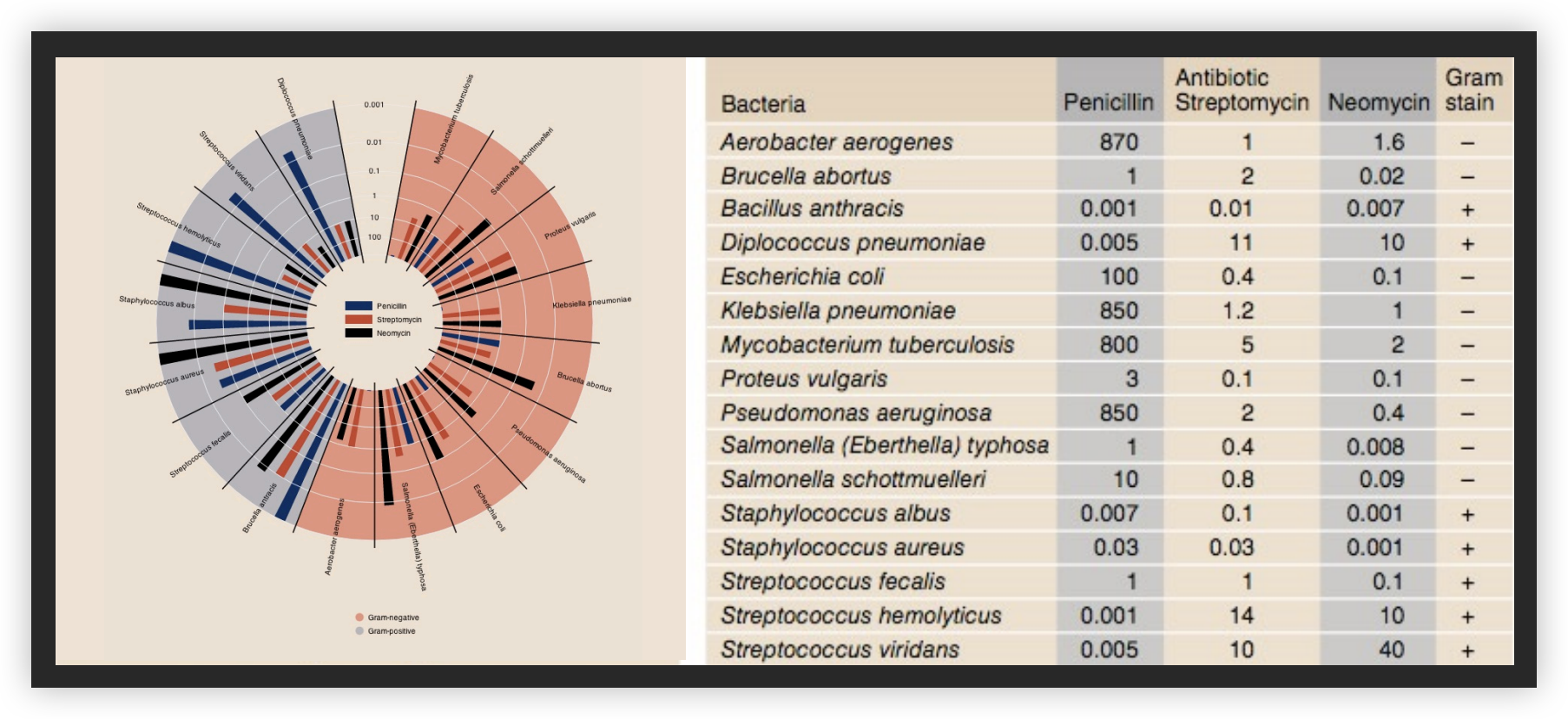
分析示例:抗生素的有效性
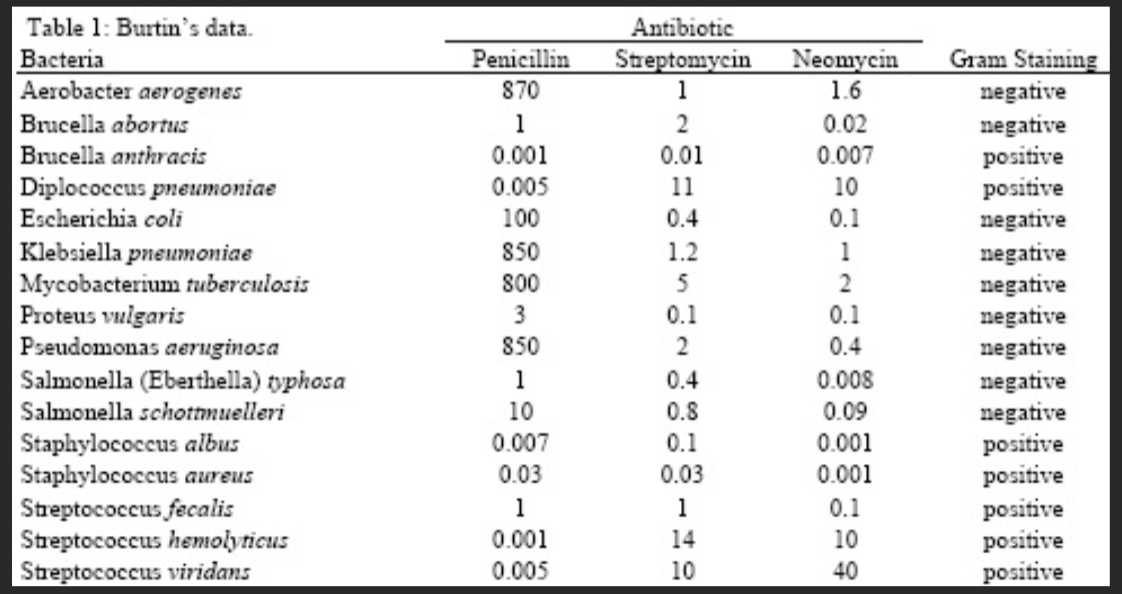
1951 年之前收集
Will Burtin, 1951
半径:1/log(MIC) 条形颜色:抗生素 背景颜色:革兰氏染色
Wainer & Lysen, American Scientist, 2009

探索过程的教训
- 构建图形以解答问题
- 检查"答案"并评估新问题
- 重复上面的过程!
适当地转换数据(例如,反转、取对数)
"展示数据变化,而非设计变化"
-Tufte
Tableau/Polaris
- 探索性分析可能结合 图形方法和统计学
- 使用问题来发现更多问题
- 交互对于探索大型 多维数据集至关重要
不是我关注的重点,所以我跳过了。